February 09, 2016
tl;dr I've decided to put the efforts Grawl deserves.
Grawl is a crawler that finds broken links on your
websites and alerts you.
A Two Year Pause
I've been extremely busy over the last two years. I have been freelancing with
10x Management. They bring me a lot of fun
projects to work on, they are awesome! I also had a baby, she turned 2 a few
days ago. For those who have had babies, you understand how time consuming it
can be! I also spent about a year in Spain, which implies first moving to
Spain, and then moving back to Canada.
During those two years, I have put aside pretty much every other projects I
had. Building robots and electronic projects, playing music, doing
kung fu, building startups.
But now! It's time to get back to building startups!
As some of you may know, in the past, I cofounded
Signsquid, an electronic signature web application.
I was also part of the early days of Snipcart,
an HTML and JavaScript shopping cart, which is really taking off!
I'm a software developer, so when I was part of those projects, I was
mostly concerned with the technical aspect. I've never spent much time doing
the business part: marketing, closing deals, etc. I've always lived with the
idea that I could not do it myself, that I needed other cofounders to do it.
But these days are over!
Now, I'm not saying that I'm not welcoming a business guy as a cofounder! I'm
saying that I don't want to wait for the perfect cofounder.
Grawl, The Project That Needed Some Love
Last week, I've read a blog post by Nathan Barry. It's called
Knowing When to Quit. To summarize a little
bit, he says that when a project is just sitting there and doing nothing,
you should either kill it or give it the effort it deserves. It's really a
great blog post that inspired me, because I have this project I did back in
2012-2013.
Grawl.
It was never quite the MVP I needed to test the market fit. It was abandoned.
Here's a screenshot of how it looks like today (February 2016) and have been
for the last few years:
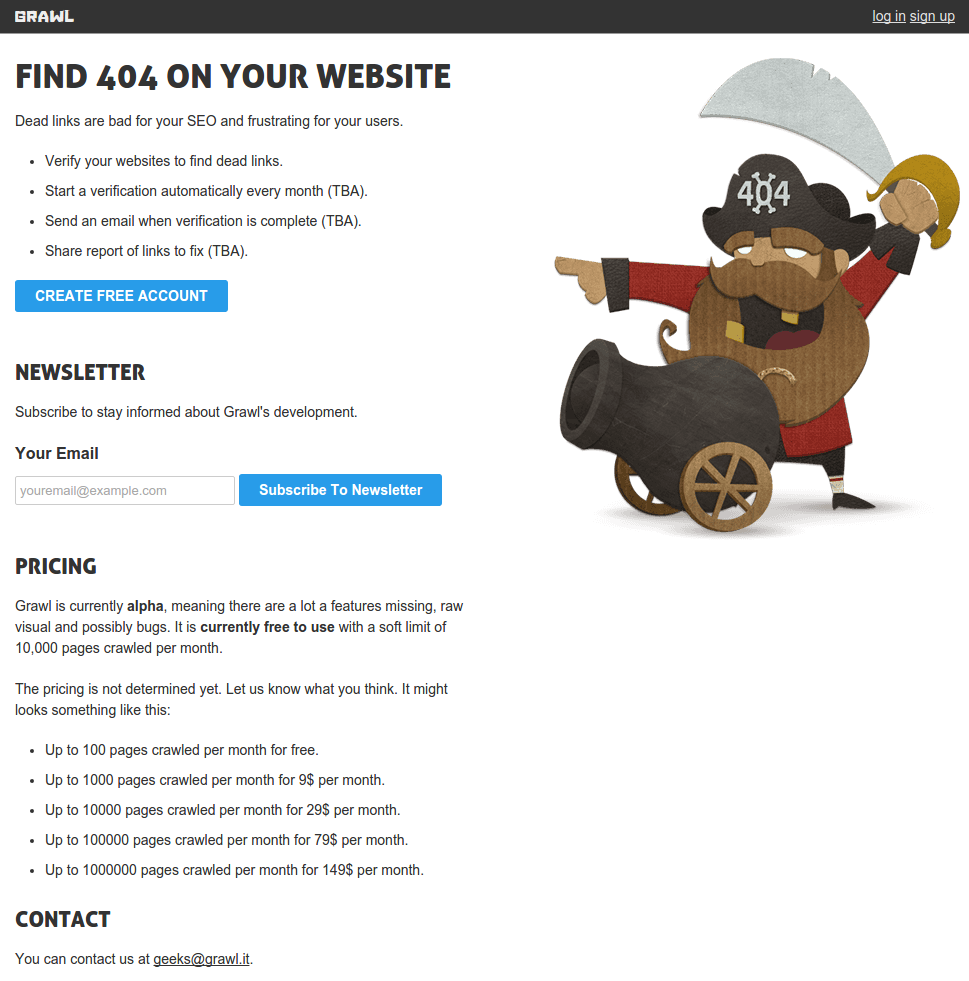
Grawl, at its heart, is a SaaS that will find broken links on your websites.
For example, it will find links that point to 404. The main difference with
existing tools, like Google Webmaster Tools, is that Grawl will keep the list
of websites you have and alert you by email when it finds broken links. It
crawls all of your websites every months and it sends you an email when it's
done. Also, since it's a specialized tool for broken links, it opens the door
to cool features, like providing an actionable checklist of all the links to
fix, etc.
It's not revolutionary, but I'm sure it has value for someone. Agencies?
Big website maintainers?
The 100 First Paying Customers
At the time of writing, there are 11 users in the database. Mostly people that
I told about the project in 2012-2013. We could say 0. Also, since there
is currently no way to get a paying account, they are not paying customers.
Let's change that.
My first few steps toward my goal of getting 100 paying customers will be:
- Update the code base and infrastructure to 2016 (more on that below).
- Add the ability to charge customers: plans, credit cards, etc.
- Build a real MVP website.
After that, I will be ready to attack the market.
Regarding updating the code base to 2016, I don't plan to rewrite anything.
It's easy to fall in the trap of changing framework for the goût du jour
framework. Here I'm talking about fixing stuff that broke over the few years
the project was abandoned, updating libraries version, having proper backups,
etc.
In Summary
This post is more or less the kickoff of my efforts to bring a new SaaS to its
first 100 paying customers. I'll try to post a lot more often, about the
progress, the strategies, the success and failures. Stay tuned!
August 27, 2014
As you may know, I am currently a freelance software developer. I write code for a living. However, I am more and more intereseted in building things that are not emprisoned in a screen. I've been playing with Arduino for a while now and I thought I would try using the AVR chips directy instead of relying on Arduino.
So I bought a few ATmega168's on ebay and an usbasp. Well, a cheap Chinese version of usbasp but it feels solid and is pretty small.


Then I decided to try my new things. I connected all the wires properly and plugged the usbasp in my laptop. I run Ubuntu 14.04 as I do this if that might help others in the future. First thing is to try to speak to the ATmega168:
avrdude -p atmega168 -c usbasp
I got this error message:
avrdude: Warning: cannot query manufacturer for device: error sending control message: Operation not permitted
avrdude: Warning: cannot query product for device: error sending control message: Operation not permitted
avrdude: error: could not find USB device with vid=0x16c0 pid=0x5dc vendor='www.fischl.de' product='USBasp'
avrdude done. Thank you.
I guess I can change permissions later, but for now:
sudo avrdude -p atmega168 -c usbasp
Little bit better, but still not working:
avrdude: warning: cannot set sck period. please check for usbasp firmware update.
avrdude: error: programm enable: target doesn't answer. 1
avrdude: initialization failed, rc=-1
Double check connections and try again, or use -F to override
this check.
avrdude done. Thank you.
I looked all over the web trying to figure out what was going on. Turns out the cheap Chinese usbasp's have a firmware that does not allow to set manually the clock speed. It's automatic. So when avrdude tries to set the clock speed and the usbasp does not change it, it complains. But since it's automatic, it should not cause problem. You can always try to update the firmware of your usbasp, which should let you change the clock speed manually, but you'll loose the automatic and will always have to specify it.
Since the clock speed was not the problem, I double (triple, etc.) checked the connections. I found other diagrams for the pinout of the usbasp, where every pin is reversed, mirror style. But this is just because some diagrams show the pins as they come out of the usbasp and others show it as they come out of the ribbon cable connector. After trying to reverse a few times, I found out there was a red wire in the ribbon to indicate Vcc. OK, some might think I'm stupid but when you don't know... Anyway, all my connections were right in the first place and it was not the problem.
Then I remembered that Arduino chips have some fuses set so they use an external oscillator for their clock, instead the internal clock. When the fuses are set to use the external oscillator, the chip is dead without it. So I had a look at the ebay auction where I bought the ATmega168's, and it says they are preloaded with the Arduino bootloader. Crap. And I don't have an oscillator at hand.
By searching more, I found this forum post. If you run in the same problem, I suggest you read it.
Basically, I guess the best way would have been to use an oscillator, but he suggests a few other ways to hack something to replace the oscillator. He suggests using a 555 timer at around 1 MHz. I have all that is needed, but I would have to select the proper RC components and wire all that together. Time consumming and too demanding at 2 AM. The other solution, which is nice, is that you can use another AVR chip as a clock. All my ATmega168 have an Arduino bootloader, so I can't use them right now. But I have an Arduino Uno that is very easy to program. Just plug it in USB and use Arduino IDE to upload.
So the code looks like this:
#include <avr/io.h>
int main(void) {
DDRB = 0xFF;
while (1) {
PORTB ^= 0xFF;
}
return 0;
}
I didn't translate it to Arduino, since it compiled and uploaded without complaining. You can connect any pin of PORTB of the Arduino (that is 8-13) to XTAL1 of the ATmega168.
I took the default fuses for ATmega168 of this calculator.
sudo avrdude -p atmega168 -c usbasp -U lfuse:w:0x62:m -U hfuse:w:0xdf:m -U efuse:w:0xf9:m
It worked and I can now program my ATmega168's. Hurray!
August 15, 2014
tl;dr Idempotence helps create more robust systems.
Idempotence is a mathematical concept that should be understood by all developers.
An operation is considered idempotent when doing it more than once is the same as doing it once.
For example, multiplying by 1 is idempotent.
x * 1 == x * 1 * 1
Multiplying by 0 is also idempotent.
x * 0 == x * 0 * 0
The key concept to remember is that applying the operation once can have side effects, but applying it more than once will not do anything more that what was already done the first time.
Assignment is idempotent.
x := 4
You can assign 4 to x as much as you want, x will still be 4. But assigning 4 to x one time is different than zero time.
HTTP Verbs
HTTP verbs can be classified as idempotent or not.
DELETE is an idempotent verb. No matter how many times you do it after the first time, it will give the same result as the first time. For example, DELETE /users/4/contacts/3 could remove your contact with the ID 3. If you call it again, that contact has already been removed and nothing more should happen.
GET is also idempotent. In fact, it's more than idempotent. It is considered a safe method. Safe methods can be compared to multiplying by 1. Doing it zero, once or more times should have the same effect. All GET does is get a resource. For example, you should never use normal links to delete resources.
POST is not idempotent. Every time you do it, you can expect a side effect to happen. For example, every time you POST a contact form, an email is sent.
When it comes to APIs, that concept is well understood by consumers and providers. Designing around it will result in least astonishment.
See Wikipedia: Safe Methods and Idempotent methods.
Message Queues
Let's say you build a web app to manage events. You can add people to the invitees of an event. In other words, an event has many invitees. For quicker response time, you decided to send all emails from a worker. So when a user finalizes an event, a message is queued. A worker gets that message and sends the invite emails for that event.
This is a really common pattern, and if you are not doing it that way, you should really start to.
You realize that you had an SMTP problem and all your emails have not been sent for some time, and it's not even showing up in the logs! You think "oh, well, I'll just call the function to send the emails again", but you don't know for which events you should call that function.
Here comes idempotence.
When you execute a task in a worker, always make sure it's idempotent
For the email example, every time you send an email to an invitee, you can keep the datetime in the database, in the event invitee row. If it has already been sent (sent datetime is not NULL), don't send it again. As easy as that. Also, you might want to check if the event is finalized. If not finalized, do nothing.
More generally:
- Check that your job is ready to be executed (e.g. event finalized). If not, do nothing.
- Check that the job has not already been done. If done, do nothing.
- Do job, keep datetime or something else in the database, log that it has been done (e.g. "INFO Invitation email for event 234 has been sent to john.doe@example.com").
- Keep jobs granular. You have 5 emails to send? Queue a job (e.g.
send_event_emails(event_id)) that will queue the 5 other jobs (e.g. send_event_email_to_invitee(event_id, invitee_id)).
You realize something went wrong? You can always call your function to send emails on all events. Still crashed when half of the emails were sent? Fix what was wrong and just call it again. Also, it's easy to inspect what emails have not been sent yet. Bonus, you can do some intelligence with the datetimes (how many emails a day do we send? what are the peak hours?).
Also, some message queues don't garantee that a message will be delivered only once. Amazon SQS is that way. Your workers should really only do idempotent tasks.
SQL Migrations
In the same spirit as the worker example above, when you do an SQL migration, do it in an idempotent way when possible.
For example, you decide to split the user table in two tables. One for basic informations (users) and one for all details that are not always important (profiles). You put a foreign key user_id in the profiles table. You have a migration that takes every row in users (SELECT * FROM users) and inserts a row in profiles with user data. You run it, and well, it crashes midway after 1 hour, because of some NULL value you didn't think about. You fix it and run it again, but you then realize that some users have already been processed and have two profiles.
The idempotent solution: instead of SELECT * FROM users, you can just select the users that don't have a profile row. That way you can run it as many times as you want. It will only process the few users that have not been processed yet. A big advantage of that method is that you can leave your app running in production while you do the migrations. When you are ready to deploy the new code that uses the profiles table, you can call your function again to make sure the latest users that signed up are also migrated. That example is not so great, because a user could change some information in the users table during the migration, but I guess you get the point.
Denormalized Data
You have an application where each user has many documents. They can search their documents by tags. Tags come from many sources. The title of the documents, the folders, actual tags, the names of the authors, etc. You decided to keep a table named tags where you keep all the tags for every documents, it looks like this: id (hash), tag (actual text of the tag), document_id (foreign key to the document). When you add an author to a document, it does an insert in the tags table. When you remove an author, it finds the good tag and removes it.
Someday, you see in the log there was an error every once in a while when inserting a tag because of an obscure character encoding issue. You fix the issue and deploy the new code. However, there are a lot of missing tags and you have no easy way to fix it manually.
Instead of just having functions of the type add_tag_for_new_author, you should have a function of the type update_tags_for_document. When you call that function, instead of just adding a tag for the author that was just added, it checks all the document, rebuilds the tags list and makes sure that the correct data is in the database. That way, the tags table is really managed as it should be: a cache. You could delete all rows from that table and just call update_tags_for_document on every documents. It takes 2s to update the tags for a document? Let the worker do it, queue a message.
Conclusion
If you were not aware of idempotence, I hope I convinced you to use it. Also, please note that I kept the examples simplistic for educational purpose.
« Previous Page
|
Next Page »